
强化学习

强化学习
flowwalker强化学习(Reinforcement Learning)
Agent 与 Environment 交互–试错→奖励惩罚→学习
Reward → Policy
理论基础
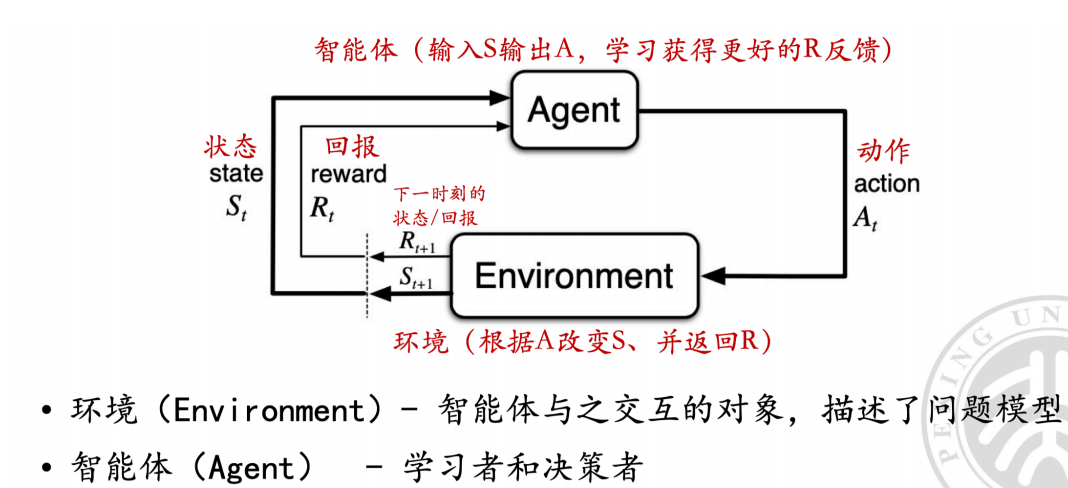
问题建模
环境
- 初始状态 $$S_0$$
- 当前玩家 C
- 动作 A : 每个状态下智能体可以选择的合法动作集合
- 状态转移 P : $$P(S_{t+1} \mid S_t , A_t)$$
- 奖励 R : $$R_t \leftarrow S_t , A_t$$
- 终止状态 $$S_T$$ : 达到状态后, 任务终止
衡量环境复杂度的两个关键空间:
- state space : 所有可能到达状态的集合
- action space : 所有状态下可采取的动作集合
注意: 状态转移的不确定性 既可能来自于环境本身,也可能来源于策略
转移概率P的内在随机性
( 环境反馈的不确定性, 即使同一环境和动作也可能返回不同的结果)
P依赖于动作的选择分布
(动作中含有stochastic policy成分, 带来转移的不确定性)
智能体
Policy
核心
\pi$$ 表示智能体在**各个状态**下**选择动作的规则或者映射关系** - 必须**全局定义** : 每一个可能状态都需要给出一个动作选择 - **确定性策略** : 对于每个状态 $$ s \in S$$, 总是返回一个确定的动作 $$ a \in A
目标
寻找最优策略 $$ \pi^* $$ , 使从初始状态 $$ S_0 $$ 到终止状态 $$ S_T $$ 所得到的总奖励最大:
即 $$G=E [\sum_{i=1}^{T} R_i]$$ 最大
我们假定:
- 敌人采用确定性策略
- 可以通过多次对弈学习到更优的对策策略
(因为敌人可能犯错, 而我们可以据此调整和修改)


喜欢这篇文章的人也看了



评论
匿名评论隐私政策


